Hypothesis Testing¶
Hypothesis testing is a statistical method that is used in making a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
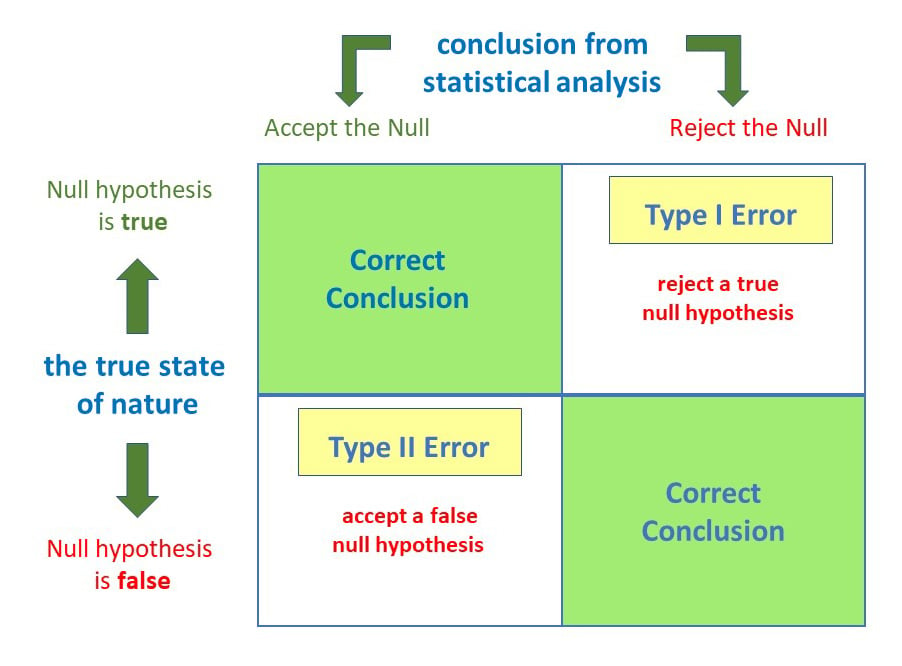
The purpose of a hypothesis test is to determine whether the null hypothesis is likely to be true given sample data. If there is little evidence against the null hypothesis given the data, you accept the null hypothesis. If the null hypothesis is unlikely given the data, you might reject the null in favor of the alternative hypothesis
Definitions:
Null Hypothesis, $H_0$: The null hypothesis assumes that nothing interesting is going on between whatever variables you're testing. The exact form of the null hypothesis varies from test to test: if you're testing whether two groups are different, the null hypothesis states that the groups are same. For example, if you want to test whether the average age of voters in your home state differs from the national average, the null hypothesis would be that there is no difference between the average.
Alternative Hypothesis, $H_1$: The alternative hypothesis assumes that something interesting is going on between the variables you're testing. The exact form of the alternative hypothesis will depend on the specific test you are carrying out. Continuing with the example above, the alternative hypothesis would be that the average age of voters in your state does in fact differ from the national average.
Significance Level, $\alpha$: It refers to teh degree of significance in which we accept or reject the null hypothesis. 100% accuracy is not possible for accepting a hypothesis, so we, therefore select a level of significance that is usually 5% (0.05).
$$\text{Significance level}, \alpha = 1 - \text{Confidence Level}$$or (in percentages)
$$\text{Significance level}, \alpha = 100 - \text{Confidence Level}$$For example, If the confidence level is 95% (0.95) then the significance level is 5% (0.05).
p-Value: After carrying out a test, if the probability of getting a result as extreme as the one you observe due to chance is lower than the significance level, you reject the null hypothesis in favor of the alternative. This probability of seeing a result as extreme or more extreme than the one observed is known as the p-value.
Types of Tests¶
There are different types of test, here are the ones which we will cover:
- t-Test: Genrally used for small sample sizes $(n < 30)$, and when population's standard deviation (or variance) is unknown.
- z-Test: Generally used for large sample sizes $(n \ge 30)$, and when the population's standard deviation (or variance) is known.
- F-Test (ANOVA): Used for comparing values of more than two variables.
- Chi-Square Test: Used for comparing categorical data.
Note: Most parametric tests, require a population which is somewhat normally distributed. If not, apply normalization to the dataset.
One-Tailed Test vs. Two-Tailed Test¶
One-Tailed Test:
- A one-tailed test may be either left-tailed or right-tailed.
- A left-tailed test is used when the alternative hypothesis states that the true value of the parameter specified in the null hypothesis is less than the null hypothesis claims.
- A right-tailed test is used when the alternative hypothesis states that the true value of the parameter specified in the null hypothesis is greater than the null hypothesis claims.
Two-Tailed Test:
- The main difference between one-tailed and two-tailed tests is that one-tailed tests will only have one critical region whereas two-tailed tests will have two critical regions. If we require a $100(1 - \alpha)$ % confidence interval we have to make some adjustments when using a two-tailed test.
- The confidence interval must remain a constant size, so if we are performing a two-tailed test, as there are twice as many critical regions then these critical regions must be half the size. This means that when we read the tables, when performing a two-tailed test, we need to consider $\alpha / 2$ rather than $\alpha$.